넷플릭스의 영화 추천 알고리즘
다양한 알고리즘을 복합적으로 사용합니다.


<넷플릭스 인사이트>에 소개된 내용을 바탕으로 정리했습니다.
넷플릭스 회원은 10~20개 타이틀 검토 후
영화를 결정하지 못하면 60~90초 후에 흥미를 잃는다.
OTT 서비스 경쟁이 치열해지면서 양질의 콘텐츠를 확보하는 것과 더불어 고객을 자주 방문하게 만들고 최대한 오래 붙잡아 두는 게 OTT 플랫폼 성공의 핵심 요소입니다. 콘텐츠 보유 정도가 플랫폼별로 비슷하다고 했을 때 보유 타이틀을 얼마나 잘 활용하는지가 핵심 경쟁력이 될 수 있는데요. 넷플릭스는 DVD 대여 사업을 했을 때부터 축적된 노하우를 바탕으로 고객이 선호하는 타이틀을 기가 막히게 찾아줍니다.
넷플릭스는 고객의 70~80%가 추천 콘텐츠를 시청한다고 합니다. 이번 글에서는 넷플릭스의 추천 알고리즘을 간단히 소개해보겠습니다. 전문적으로 들어가면 너무 깊어서 딱 읽기 좋은 정도로 정리했습니다.
1. 유사 사용자 기반 알고리즘
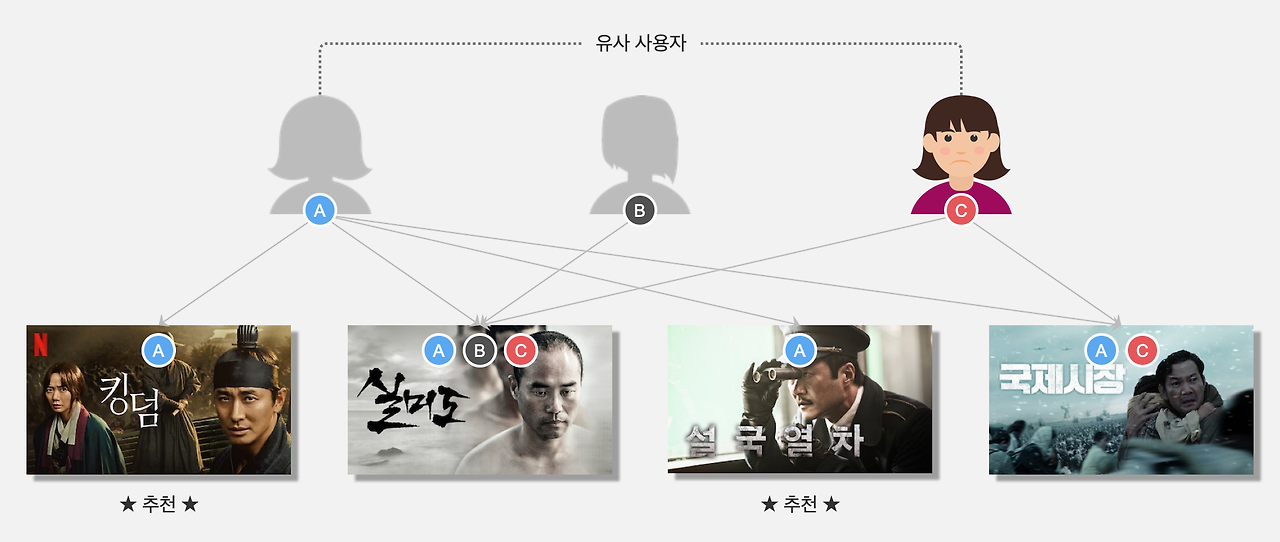
위 이미지를 보면 A, B, C 유저가 있습니다. 우리가 영화를 추천해야 할 타깃 유저는 C인데요.
사용자 기반 알고리즘은 C와 취향이 비슷한 유사 사용자를 찾아내 영화를 추천해주는 방식입니다.
A는 킹덤, 실미도, 설국열차, 국제시장을 시청했고.
B는 실미도만 시청했고
C는 실미도, 국제시장을 시청했습니다.
C와 중복되는 영화를 시청한 유저는 A입니다.
그래서 A와 C를 유사 사용자로 묶고, A는 시청했는데 C는 시청하지 않은 킹덤과 설국열차를 추천합니다.
2. 유사 아이템 기반 알고리즘
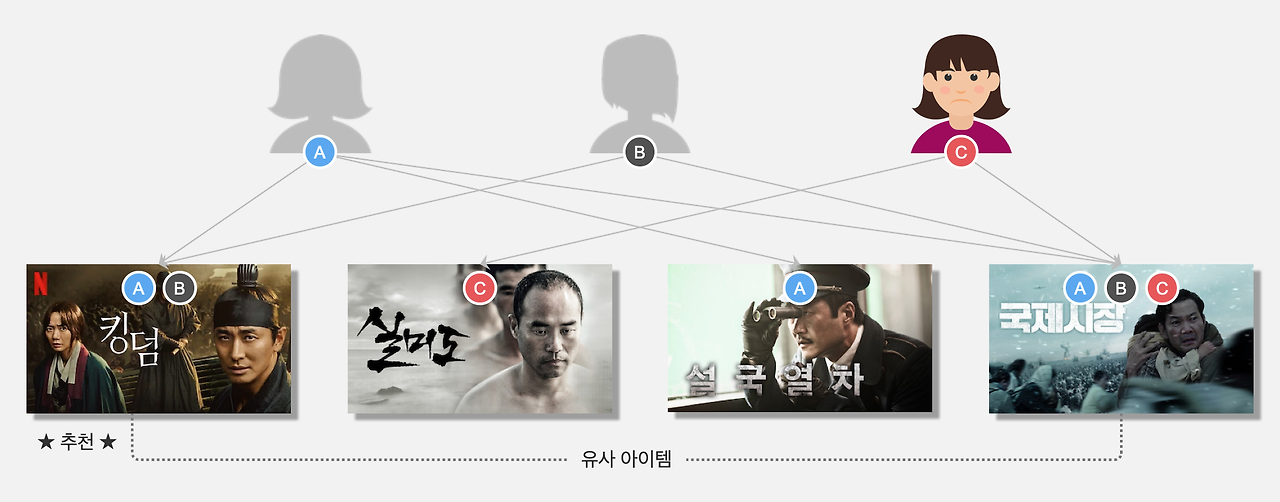
아이템 기반 알고리즘은 영화와 영화 간의 시청기록을 파악해서 유사한 아이템을 추천해주는 방식입니다.
위 이미지에서 타깃 사용자 C의 시청기록을 제외하고, A와 B의 시청기록을 보겠습니다.
A는 킹덤, 설국열차, 국제시장을 시청했고,
B는 킹덤, 국제시장을 시청했습니다.
A와 B의 시청기록을 바탕으로 킹덤과 국제시장을 유사 아이템으로 묶을 수 있고,
국제시장을 시청한 타깃 유저 C에게는 아직 시청하지 않은 킹덤을 추천합니다.
지금 소개한 사용자&아이템 기반 알고리즘은 이미 많은 플랫폼에서 사용하고 있습니다. 유사도 계산이 간단하고 예측 평점을 구하기 쉽다는 장점이 있지만 몇 가지 문제점도 있습니다.
- 콜드 스타트 : 새로운 유저나, 새로운 아이템이 추가되었을 때 유사도를 계산할 수 있는 데이터가 부족해 정확한 추천을 하기가 어렵습니다.
- 계산량 : 사용자와 유저가 추가될 때마다 계산량이 많아져서 부하가 증가됩니다. 넷플릭스 유저는 4억 명 정도라고 하는데요. 유저 1명, 타이틀 1개 추가될 때마다 계산량은 어마어마하게 늘어나게 됩니다.
- 롱테일 : 일반 사용자들은 소수의 인기 항목에만 관심을 보이기 때문에 관심이 적은 비인기 항목에는 추천 정보가 부족합니다.
그래서 넷플릭스는 위 2가지 방식 외에 2가지 방식을 더 사용합니다.
3. 잠재 모델 기반 알고리즘
잠재 모델 기반 알고리즘은 항목 간 유사성을 단순하게 비교하는 방식이 아니라 사용자와 아이템에 내재된 잠재 모델의 패턴을 이용하는 방법입니다. 예를 들어 킹덤을 좋아하는 사용자는 배우 주지훈을 좋아해서 일수도 있고, 좀비물을 좋아해서일 수도 있고, OST를 좋아해서 일수도 있습니다.
그래서 특정 기준을 바탕으로 행과 열을 분해해서 예측 평점을 구합니다.

위 이미지는 <장르>를 기준으로 행과 열을 분해한 예시입니다.
킹덤, 이태원 클라쓰, 설국열차의 장르 비중은 넷플릭스가 신규 콘텐츠를 생성할 때 콘텐츠 전문가가 직접 시청하고 메타 데이터에 등록합니다. 킹덤의 경우 로맨스 1점, 액션이 3점이다라고 미리 지표화를 해놓는 거죠.
그리고 사용자의 시청 데이터를 바탕으로 사용자별 장르 선호도를 값으로 산출합니다. B의 경우 로맨스 선호도와 액션 선호도가 각각 1점입니다. 이 데이터를 바탕으로 아직 시청하지 않은 이태원 클라쓰와 설국열차의 예측 평점을 4점, 4점으로 쉽게 구할 수 있습니다.
잠재 모델 기반 알고리즘은 차원이나 사이즈가 매우 작아서 스토리지도 크게 차지하지 않는 장점이 있습니다.
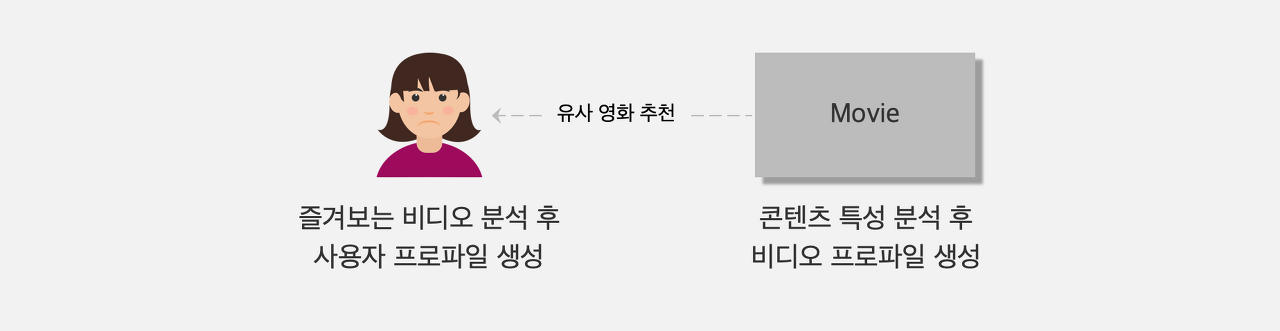
4. 콘텐츠 기반 알고리즘
위에서 소개한 사용자 기반, 아이템 기반, 잠재 모델 기반 알고리즘은 사용자와 아이템 사이의 연관성 파악이 분석 대상이지만 콘텐츠 기반 알고리즘은 사용자와 아이템간의 정보가 필요하지 않습니다.
영화 타이틀을 기준으로 배우, 장르, 국가, 시대, 연령대 등 수백 개의 영화 특성을 분석해 영화 프로파일을 생성하고, 타깃 사용자가 좋아한 영화를 바탕으로 사용자 프로파일을 도출합니다. 그리고 영화 프로파일과 사용자 프로파일을 비교해서 사용자 선호 영화를 추천하는 방식입니다.
네, 여기까지 ①사용자 기반 알고리즘 ②아이템 기반 알고리즘 ③잠재 모델 기반 알고리즘 ④콘텐츠 기반 알고리즘을 살펴봤는데요.
①②번은 유사도 계산이 간단하고 예측 평점을 구하기 쉬운 반면에 콜드 스타트, 계산량, 롱테일 이슈가 있습니다. 그래서 데이터가 적어도 추천이 가능한 ③④번 알고리즘이 등장했고 넷플릭스는 ①②③④번을 포함한 다양한 알고리즘을 mix 한 하이브리드 추천 시스템을 적용하고 있습니다.
현재 넷플릭스에는 2,000여 개의 취향 그룹이 있고 이 취향 그룹은 계속해서 업데이트된다고 합니다.
또한 넷플릭스가 영화를 추천하면서 알게된 사실은 2016년 이전까지는 사용자의 국가/지역에 따라 선호하는 영화가 다를 것이라고 예상하고 국가별 사용자별 다른 콘텐츠를 추천했지만 실제 연구 결과 그렇지 않다는 사실을 발견했고 130개 국가로 진출한 이후부터는 국가/지역에 따른 추천 시스템은 폐지하고 취향 그룹에 따른 추천 시스템을 사용하고 있습니다.
1점~5점으로 영화를 평가하는 별점 평가 시스템도 폐지했습니다. 배경은 유명 평론가나 지인이 높은 점수를 주었을 때 내가 생각하는 별점을 주지 않고 제삼자의 관점에서 객관적으로 영화 품질을 평가해 오차가 발생한다는 점을 문제점으로 인식했고 이를 대체하기 위해 좋아요, 싫어요 두 가지 기준으로 평가제도를 개편했습니다. 평가제도 개편 후 평가 활동은 두 배 이상 늘었고 현재는 고객 시청기록과 좋아요, 싫어요 평가를 바탕으로 영화를 추천하고 사용자가 얼마나 좋아할지 예측하는 매치 지수를 숫자로 보여주고 있습니다.
네, 여기까지 <넷플릭스 인사이트> 도서에 소개된 내용을 바탕으로 추천 알고리즘을 간단히 정리해봤습니다.
책에는 훨씬 더 방대한 내용이 있으니 관심 있는 분들은 꼭 한 번 읽어보시길 추천합니다.
저는 요즘 넷플릭스 CEO가 출간한 <규칙 없음>이라는 책을 읽고 있는데요. 이 책도 흥미롭고 재밌습니다. 스타트업 경영진, HR팀에서 보시기를 추천드립니다 ^^
넷플릭스 관련 도서 링크
관련 시리즈 글 (20)
- 요구사항은 무엇을 토대로 구체화할 수 있을까요?
- 한 장의 이미지로 압축한 제품 개발 프로세스 맵!
- 기획서 완성도가 떨어지고 보기가 어려워요!
- 넷플릭스의 영화 추천 알고리즘
- 개발자 윌슨의 테스트 시나리오!
- 주니어 기획자를 위한 추천도서!
- ONDA 기획자 스터디, 아이디어/UX 분석/PM
- ONDA 기획자 스터디, 트리플 서비스 분석
- ONDA 기획자 스터디, 지그재그 서비스 분석
- API가 뭔가요? (비개발자용)
- 딱 한 달 동안 나만의 웹사이트 기획하고 만들기!
- 웹/모바일 서비스 검수 시나리오 (테스트 시나리오)
- 회의 시간을 반으로 줄이는 기획 리뷰 노하우
- 신규 Web & Mobile 서비스 구축 프로세스
- 한 번쯤 들어봤던 화면설계 & 프로토타이핑 툴 총정리
- 기획자에게 꼭 필요한 산출물 모음 (웹만사 맥비님 자료 링크)
- 웹 서비스 구축 체크리스트
- [웹 기획] 화면 설계 용어 정리
- [웹사이트 운영 팁] VOC를 근거로 한 서비스 개선방법
- 개발자와 효과적으로 커뮤니케이션하는 방법